
Die IOTA-Foundation hat ihre Zusammenarbeit im Projekt Alvarium angekündigt. Die Linux-Foundation hat dies in ihrer Presseaussendung zum Thema Project Alvarium natürlich auch bestätigt.
Wie ich in meinem Artikel IOTA – Konsistent mit der Inkonsistenz bereits ausgeführt habe, neigt die IOTA-Foundation in ihrer PR-Arbeit zu übertreiben und Pläne wie umgesetzte Errungenschaften hoch zu jubeln. Vermeintlich gehört sich das auch so für eine ordentliche PR-Abteilung. Meiner sensiblen Technikerseele schmerzt es allerdings, denn ich meine, wo viel gejubelt wird sollte davor viel programmiert worden sein.
Leider hat sich, jedenfalls von den Artikeln die ich zu dem Thema auf den Krypto-News-Seiten gesehen habe, niemand die Mühe gemacht zu erklären was Project Alvarium ist und warum man das auch kritisch betrachten sollte.
Project Alvarium – Monitoring- und Überwachungsinfrastruktur
Um was geht es bei Project Alvarium? Bei diesem Projekt geht es darum Daten zu sammeln und deren Herkunft und Integrität in einer digitalen Wertschöpfungskette sicher zu stellen. Der Startpunkt für die Datensammelei ist dabei das IT-System selbst. Damit reicht die Wertschöpfungskette von eingebauten Chips auf dem Motherboard über die Cloud-Lösung zur Auswertung hin zu DLTs zur Abspeicherung.
Dazu soll allerdings kein neuer Standard entwickelt werden, sondern existierende Technologie in einem Rahmenwerk so zusammengeführt werden, damit die jeweilige Technologie ihre Stärken ausspielt und im Zusammenspiel die bedarfsorientierte Gesamtlösung entsteht. (Warum das Sinn macht, bringt der XKCD Standard Webcomic auf den Punkt.)
Ähnlich wie bei einem modernen Auto, schlummert unter dem bekannten User-Interface des Lenkrads und der Pedale ausgeklügelte Motoren- und Steuerungstechnologie. Verbrauch aber auch Sicherheit soll für den Benutzer völlig transparent optimiert sein. Wäre dem nicht so und der Lenker müsste vor jeder Fahrt alle Systeme neu parametrisieren, würde das ähnlich zu einem Flugzeug-Cockpit aus den 80ern aussehen und wir müssten tausende Kippschalter in den passenden Zustand kippen.
Trust Insertion Technology – der Kippschalter des Datenanalysten
Im Falle des Projekts Alvarium wird nicht die Komplexität eines modernen Verbrennungsmotors samt Brems- und Steuerungsanlage hinter einfachen Bedienelementen versteckt, sondern Technologie die Datenauthentizität und Datenintegrität sicherstellen soll. Diese sgn. „Trust Insertion Technologie“ bestätigt, mit einer gewissen und vor allem beschränkten, Glaubwürdigkeit die Korrektheit der Daten und deren Metadaten. Damit ist nicht nur klar, dass die Daten korrekt sind bzw. mit welcher Wahrscheinlichkeit, sondern auch die Behauptungen von wo und wann sie stammen.
Da gibt es natürlich die verschiedensten Ansätze. Wie oben bereits angedeutet, kann das schon auf Siliziumbasis auf dem Motherboard in Chip-Form passieren. Das von Hackern und Datenschützern kritisierte([1], [2]) Trusted Platform Module ist dabei nur eine Möglichkeit.
Auch später, zB. in einer Virtual Machine oder in der Anwendung selbst, kann das passieren. In der Überblicks-Präsentation (s. 6) zu dem Projekt, werden sieben Ebenen für diese Trust Insertion Technologies definiert:
- Hardware Root für die Bereitstellung von Signaturen und Gerätedaten
- Services zur Identitäsfeststellung in einer IT-Infrastruktur
- Interfaces zu Hardware-Daten (zB. welche Signale auf welcher Schnittstelle ausgingen)
- Sichere Laufzeitumgebungen für Anwendungen
- Verwaltungssoftware für Datenpolizzen
- Storage für die Daten
- Distributed Ledgers um die in Ebene 1 bis 6 erzeugten Assets zu registrieren.
Jede dieser Ebenen definierte mehrere Technologien die man verwenden könnte, teilweise sind sie auch voneinander abhänging. Damit wird’s natürlich schwierig und unübersichtlich wenn man nun die Benutzerdaten verwalten möchte und sich plötzlich nicht nur mit der Parametrisierung seiner VMs sondern auch der Laufzeitumgebung sowie der Storage-Lösung beschäftigen muss.
Die Abstraktion bzw. die Vereinfachung die Projekt Alvarium bringen soll ist ein sgn. Data Confidence Fabric (kurz DCF). Solche DCF stellen Schnittstellen für die Ein- und Ausgabe bereit und erlauben es so Programmierern, völlig unabhängig von der eingesetzten Technologie, die Lösungen zu bespielen.
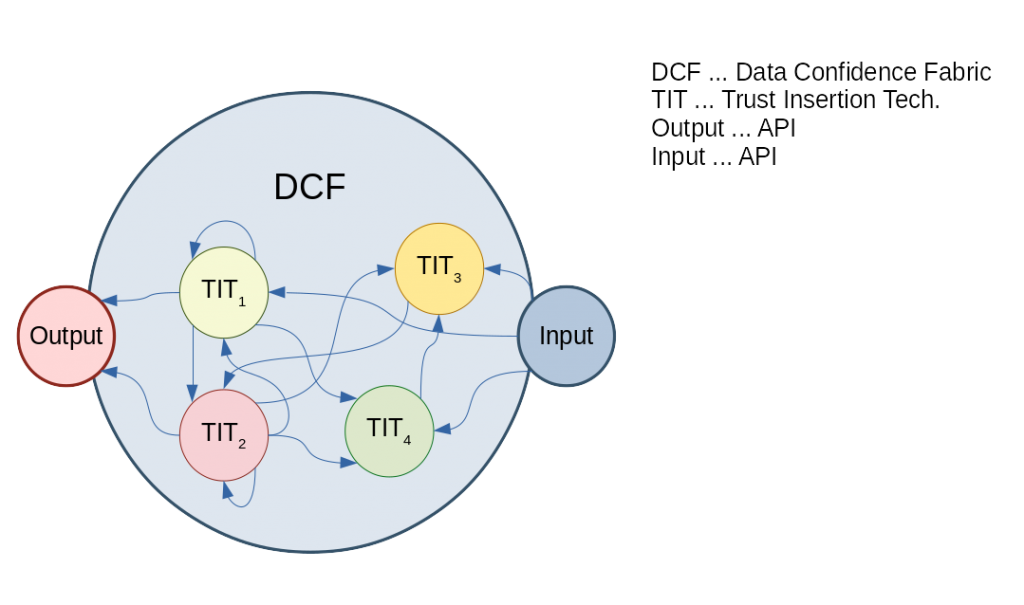
Ein DCF soll dann Möglichkeiten bieten die Daten transparent für den Verwender zu löschen aber auch zu bestimmen wie glaubwürdig ein Datensatz ist.
IOTA und Project Alvarium
Wo betritt nun IOTA das Bild? IOTA ist eine der möglichen DLTs aus der oben genannten Ebene 7. Nicht mehr, aber auch nicht weniger, beschreibt die Rolle von IOTA in diesem Projekt.
In der Präsentation wird zu aller Erst Hyperledger genannt – was Sinn macht, da es sich dabei auch um ein Linux Foundation Projekt handelt. Danach folgen IOTA und Ethereum.
Engmaschige Überwachung und die Kryptoszene
Diese Technologie dient der besseren Auswertung unserer Daten. Es wird zwar behauptet, es diene auch dazu, das Recht auf Vergessen der EU-Datenschutzgrundverordnung durchzusetzen, aber das löst das Problem nicht, dass sehr wertvolle, da sehr glaubwürdige und automatisiert auswertbare, Daten erzeugt werden.
Wenn diese dann gelöscht werden ist das gut. Besser wäre es gewesen sich gegen deren Erstellung zu schützen!
Wie News-Outlets der Kryptoszene so etwas blind hochjubeln ist mir völlig unverständlich. Nicht vergessen, die Wurzeln liegen immer noch bei den Cypher-Punks! Also mein Appel an euch: Kritisch bleiben, im Zweifelsfall Originalquellen prüfen und nicht jeden Mist glauben den man liest. (Auch meinen nicht)
PS: Wer des Englischen mächtig ist und sich für eine „sanfte“ Einführung in die Überwachungsproblematik interessiert, dem empfehle ich den Edward Snowden JRE-Auftritt